
وقتی از نرمافزار دستیار هوشمند سیری (Siri) سوال میپرسید یا یک موضوع خاص را در گوگل جستجو میکنید، از مفهوم تکنولوژیکی بهنام یادگیری ماشین یا ماشین لرنینگ (Machine learning) استفاده میکنید. اصلا عجیب نیست. یادگیری ماشین در عصر دیجیتال با زندگی روزمره همه ما گره خورده است. حتی نحوه ارائه فیدهای اینستاگرام و توییتر یا پیشنهادهای یوتیوب با ماشین لرنینگ مدیریت میشود. سیستمهای هوشمند ماشینها یا تشخیص پزشکی و ساخت دارو و… نیز همگی به یادگیری ماشین متکی هستند.
دنیای پیشروی ما دنیایی است که از بازار تولید و صنعت گرفته تا بازار کار و حملونقل و بهداشت و درمان همگی نیازمند ابزارها و پلتفرمهای مربوط به هوش مصنوعی و ماشین لرنینگ خواهد بود. شاید ورود به این دنیای هیجانانگیز و ناشناخته که میتواند تضمینکننده موفقیتهای شغلی و اجتماعی شما باشد کمی ترسناک بهنظر برسد. اما نگران نباشید از این مقاله شروع کنید تا هرچیزی که برای آموزش ماشین لرنینگ نیاز دارید را با هم مرور کنیم.
ماشین لرنینگ چیست و چرا مهم است؟
ماشین لرنینگ (Machine Learning) یا یادگیری ماشین شاخهای از هوش مصنوعی یا Artificial Intelligence (AI) و علوم کامپیوتر است که روی استفاده از دادهها و الگوریتمها برای تقلید از روشی که انسانها یاد میگیرند تمرکز دارد. در واقع یادگیری ماشین به ماشینها توانایی یادگیری خودکار از دادهها و تجربیات گذشته را میدهد و در عین حال الگوهایی را برای پیشبینی با کمترین مداخله انسانی شناسایی میکند.
بهزبان سادهتر روشها و الگوریتمهای یادگیری ماشین، رایانهها را قادر میسازد تا بدون برنامهنویسی مشخص و روشن بهطور مستقل کار کنند. برنامههای کاربردی ML با دادههای جدید تغذیه میشوند و میتوانند بهطور مستقل یاد بگیرند، رشد کنند، توسعه و تطبیق پیدا کنند.
یادگیری ماشین امروز بخش مهمی از حوزه علم داده محسوب میشود. با استفاده از روشهای آماری، الگوریتمهای مختلفی برای طبقهبندی یا پیشبینی و کشف بینشهای کلیدی در پروژههای دادهکاوی آموزش داده میشوند. همین بینشها هستند که تصمیمگیری هوشمند در برنامهها و کسبوکارها را هدایت میکنند و بهطور ایدهآل بر معیارهای رشد کلیدی تأثیر میگذارند.
با توجه به گسترش و رشد اهمیت کلان دادهها (Big Data)، تقاضای بازار برای متخصصان داده هم افزایش پیدا کرده است. کار این متخصصان این است که مرتبطترین سؤالات تجاری و دادههای پاسخ به آنها را بهکمک یادگیری ماشین پیدا کنند. مثلا در چند دهه گذشته، پیشرفتهای تکنولوژیکی در زمینه ذخیرهسازی و قدرت پردازش، برخی از محصولات نوآورانه مبتنی بر یادگیری ماشین، از جمله موتور توصیهای نتفلیکس و خودروهای خودران را ممکن ساخته است.
یادگیری ماشین چه تفاوتی با یادگیری عمیق دارد؟
یادگیری ماشین به معنای یادگیری کامپیوترها از دادهها با استفاده از الگوریتمها برای انجام یک کار بدون برنامهریزی صریح است. اما یادگیری عمیق (Deep Learning) از ساختار پیچیدهای از الگوریتمهای مدلسازیشده بر روی مغز انسان استفاده میکند. در واقع شبکههای یادگیری عمیق شبکههای عصبی با لایههای متعدد هستند که میتوانند مقادیر گستردهای از دادهها را پردازش و «وزن» هر پیوند در شبکه را تعیین کنند. بهنوعی یادگیری عمیق زیرمجموعهای از یادگیری ماشین محسوب میشود که از شبکههای عصبی مصنوعی برای تقلید از فرآیند یادگیری مغز انسان استفاده میکند و پارامترهای عملکرد بهتری نسبت به الگوریتمهای ML معمولی ارائه میدهد.
درست مثل شبکههای عصبی، یادگیری عمیق بر اساس روشی که مغز انسان کار میکند مدلسازی میشود و بسیاری از استفادههای یادگیری ماشین، مانند وسایل نقلیه خودکار، چتباتها و تشخیصهای پزشکی و بهطور کلی پردازش دادههای بدون ساختار مانند اسناد، تصاویر و متن را ممکن میکند.
مثلا در یک سیستم تشخیص تصویر، برخی از لایههای شبکه عصبی ممکن است ویژگیهای فردی یک چهره مانند چشمها، بینی یا دهان را تشخیص بدهند؛ لایه دیگری هم وجود دارد که تشخیص میدهد آیا این ویژگیها منطبق بر ویژگیهای فیزیولوژیک چهره نشان داده میشود یا خیر.
عملکرد الگوریتمهای ML با افزایش تعداد نمونههای موجود در طول فرآیندهای یادگیری بهبود پیدا میکند. پس در یادگیری عمیق هرچه لایههای بیشتری داشته باشید، پتانسیل بیشتری برای انجام کارهای پیچیدهتر خواهید داشت. البته یادگیری عمیق به قدرت محاسباتی زیادی نیاز دارد و به همین دلیل در مورد پایداری اقتصادی و مشکلات زیستمحیطی نگرانیهایی را ایجاد میکند.
بهطور خلاصه تفاوتهای کلیدی این دو یادگیری را در جدول زیر میبینید:
| یادگیری ماشین | یادگیری عمیق |
|---|---|
| زیر مجموعهای از هوش مصنوعی | زیر مجموعهای از یادگیری ماشین |
| میتواند روی مجموعه دادههای کوچکتر آموزش دهد | برای آموزش به مقادیر زیادی داده نیاز دارد |
| برای تصحیح و یادگیری بهخودیخود از محیط و اشتباهات گذشته یاد میگیرد | آموزش کوتاهتر یعنی دقت کمتر و تمرین طولانیتر یعنی دقت بالاتر |
| همبستگیهای ساده و خطی ایجاد میکند | همبستگیهای غیرخطی و پیچیده ایجاد میکند |
| میتواند روی CPU (واحد پردازش مرکزی) آموزش ببیند | برای آموزش به GPU (واحد پردازش گرافیکی) تخصصی نیاز دارد |
ماشین لرنینگ چگونه کار میکند؟
الگوریتمهای یادگیری ماشین روی یک مجموعه داده آموزشی برای ایجاد یک مدل قالبگیری میشوند. پس یادگیری ماشین با جمعآوری و ثبت دادهها شروع میشود. یعنی اول باید دادهها جمعآوری و آماده شوند تا بهعنوان دادههای آموزشی ماشین مورد استفاده قرار بگیرند. هرچه دادهها بیشتر باشد، برنامه مبتنی بر یادگیری ماشین مربوط به آن بهتر خواهد بود.
این دادهها میتواند عدد، عکس یا متن باشد. از تراکنشهای بانکی گرفته تا تصاویر افراد و حتی اقلام نانوایی، سوابق تعمیر لوازم خانگی، دادههای سری زمانی از حسگرها یا گزارشهای فروش هم میتواند بخشی از دادههای مورد استفاده در ماشین لرنینگ باشند.
سپس همزمان که دادههای ورودی جدید به الگوریتم ML آموزشدیده معرفی میشود، این الگوریتم از مدل توسعهیافته برای پیشبینی استفاده میکند. در مرحله بعد دقت پیشبینیهای الگوریتم برای صحت یادگیری بررسی میشود. با توجه به نمره دقت یا الگوریتم ML مورد قبول خواهد بود و روی ماشین مستقر میشود یا مرتب با مجموعه داده آموزشی جدید تقویتشده آموزش داده میشود تا به نمره دقت قابل قبول برسد.
بهطور کلی فرآیند یادگیری یک الگوریتم یادگیری ماشین به سه بخش اصلی تقسیم میشود:
۱-تصمیمگیری: الگوریتم بر اساس برخی از دادههای ورودی، که میتوانند دارای برچسب یا بدون برچسب باشند، تخمینی در مورد یک الگو در دادهها ایجاد میکند.
۲-پیدا کردن یک تابع خطا: یک تابع خطا میزان دقت پیشبینی مدل را ارزیابی میکند. یعنی این تابع میتواند مقایسهای برای ارزیابی دقت مدل یادگیری ماشین انجام دهد.
۳-بهینهسازی مدل: اگر مدل یادگیری بتواند با نقاط داده بهتری در مجموعه آموزشی تناسب داشته باشد، وزنهای دادهها برای کاهش اختلاف بین مثال شناختهشده و برآورد مدل بهروزرسانی میشوند. الگوریتم یادگیری مرتب این فرآیند ارزیابی و بهینهسازی را تکرار میکند و وزنها بهطور مستقل تا رسیدن به آستانه دقت بالا بهروز میشوند.
در یک جمله ماشین لرنینگ در یک فرآیند تکراری استفاده از الگوریتمها برای شناسایی الگوها و یادگیری، اطلاعات دقیق و روشنی را از حجم زیادی از دادهها بهدست میآورد. درضمن الگوریتمهای ML از روشهای محاسباتی برای یادگیری مستقیم از دادهها به جای تکیه بر هر معادلهٔ از پیشتعیینشدهای که ممکن است بهعنوان یک مدل باشد، استفاده میکنند.
روشهای مختلف یادگیری ماشین کدامند؟
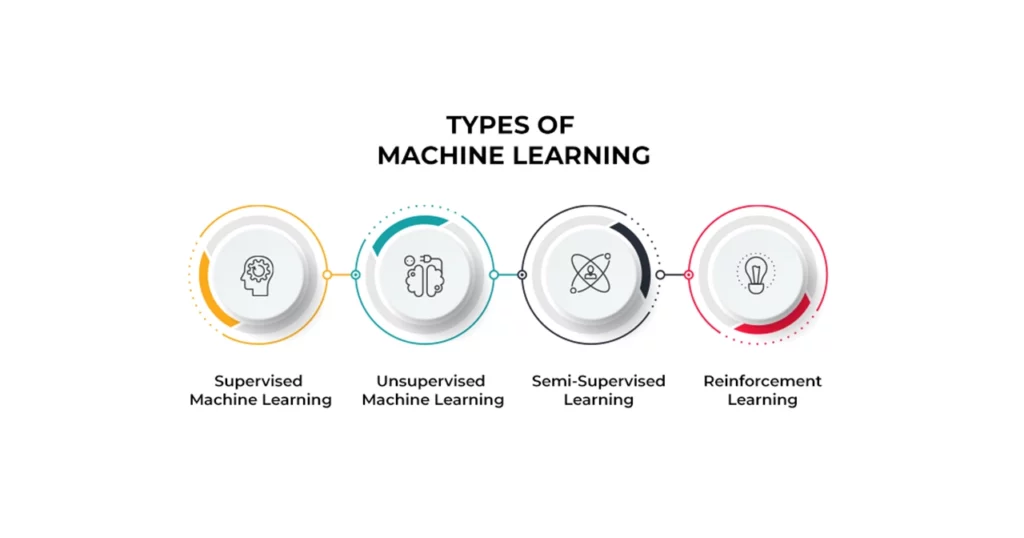
الگوریتمهای یادگیری ماشین را میتوان به روشهای مختلفی آموزش داد. طبیعتا هر روشی مزایا و معایب خودش را دارد. بر اساس روشهای یادگیری، انواع یادگیری ماشین به چهار دسته اصلی تقسیم میشوند:
۱-یادگیری ماشین نظارتشده (Supervised machine learning)
در یادگیری ماشین نظارتشده یا تحت نظارت، ماشینها و الگوریتمهای ML با استفاده از مجموعه دادههای برچسبگذاریشده آموزش میبینند و میتوانند خروجیها و نتایج را بر اساس آموزش ارائهشده پیشبینی کنند. این مجموعه داده برچسبگذاریشده مشخص میکند که برخی از پارامترهای ورودی و خروجی قبلا نقشهبرداری شدهاند. پس ماشین براساس همین ورودی و خروجی مربوطه آموزش میبیند و میتواند با استفاده از مجموعه داده آزمایشی در مراحل قبلی، نتایج مراحل بعدی را پیشبینی کند یا تخمین بزند. این نوع یادگیری به مدلها اجازه میدهد در طول زمان دقیقتر یاد بگیرند و توسعه پیدا کنند.
معمولا هدف اصلی تکنیک یادگیری نظارتشده ترسیم متغیر ورودی (a) با متغیر خروجی (b) است. مثلا مجموعه داده ورودی از تصاویر طوطی و کلاغ را در نظر بگیرید. در ابتدا دستگاه برای درک تصاویر از جمله رنگ، چشم، شکل و اندازه طوطی و کلاغ آموزش میبیند. پس از آموزش، یک عکس ورودی از یک طوطی به ماشین تحویل داده میشود و انتظار میرود که بتواند عکس را شناسایی و خروجی را پیشبینی کند. ماشین آموزشدیده ویژگیهای مختلف تصویر مانند رنگ، چشمها، شکل و غیره را در تصویر ورودی پردازش میکند تا پیشبینی نهایی را انجام دهد.
یکی از کاربردیترین استفادهها از یادگیری تحت نظارت طبقهبندی هرزنامهها در یک پوشه جداگانه از صندوق ورودی در ایمیلهاست.
۲-یادگیری ماشین نظارتنشده یا بدون نظارت (Unsupervised machine learning)
یادگیری ماشین بدون نظارت، از الگوریتمهای یادگیری ماشین برای تجزیهوتحلیل و خوشهبندی (طبقهبندی) مجموعه دادههای بدون برچسب استفاده میکند. این الگوریتمها الگوهای پنهان یا گروهبندی دادهها را بدون نیاز به دخالت انسان کشف میکنند. یعنی در این روش ماشین با استفاده از یک مجموعه داده بدون برچسب آموزش داده میشود و میتواند خروجی را بدون هیچ نظارتی پیشبینی کند. هدف یک الگوریتم یادگیری بدون نظارت هم گروهبندی مجموعه داده مرتبنشده بر اساس شباهتها، تفاوتها و الگوهای ورودی است.
بهعنوان مثال، یک مجموعه داده ورودی از تصاویر یک ظرف پر از میوه را در نظر بگیرید. در اینجا، تصاویر برای مدل یادگیری ماشین شناختهشده نیستند. هنگامی که مجموعه داده را در مدل ML وارد میکنیم، وظیفه مدل شناسایی الگوی اشیا مانند رنگ، شکل یا تفاوتهایی است که در تصاویر ورودی مشاهده میشود و آنها را دستهبندی میکند. پس از طبقهبندی، دستگاه میتواند خروجیها را پیشبینی کند.
یادگیری بدون ناظر همچنین میتواند الگوها یا روندهایی را پیدا کند که مردم به صراحت به دنبال آن نیستند. درضمن توانایی این روش در کشف شباهتها و تفاوتها در اطلاعات، یادگیری ماشین بدون نظارت را به گزینه عالی برای تجزیهوتحلیل دادههای اکتشافی، استراتژیهای فروش متقابل، تقسیمبندی مشتری، و تشخیص تصویر و الگو تبدیل میکند. مثلا یک برنامه یادگیری ماشین بدون نظارت میتواند دادههای فروش آنلاین را بررسی کند و انواع مختلفی از مشتریانی که خرید میکنند را شناسایی کند.
۳-یادگیری نیمه نظارتی (Semi-supervised learning)
یادگیری نیمهنظارتی مجموعهای از الگوریتمهای یادگیری تحت نظارت و بدون نظارت است. یعنی از ترکیب مجموعه دادههای برچسبدار و بدون برچسب برای آموزش الگوریتمهای خود استفاده میکند. در واقع این روش در طول آموزش، از یک مجموعه داده برچسبدار کوچکتر برای هدایت طبقهبندی و استخراج ویژگی از یک مجموعه داده بزرگتر و بدون برچسب استفاده میکند. یادگیری نیمه نظارتشده میتواند مشکل نداشتن دادههای برچسبگذاریشده کافی برای الگوریتم یادگیری نظارتشده را حل کند. همچنین اگر برچسبگذاری دادههای کافی برای یادگیری بسیار پرهزینه باشد با کمک گرفتن از دادههای بدون برچسب باعث کاهش هزینهها میشود.
مثلا وقتی بهعنوان دانشجو مفاهیم درسی و آموزشی را در خانه و بدون راهنمایی استاد یاد میگیریم ولی بعد از آن در یک یا چند جلسه رفع اشکال و پرسشوپاسخ از اطلاعات معلم هم برای تکمیل آموزش و بهتر فهمیدن مفاهیم استفاده میکنیم، در واقع از روش یادگیری نیمه نظارتی استفاده کردهایم.
۴-یادگیری ماشین تقویتی (Reinforcement machine learning)
یادگیری ماشین تقویتی تا حدودی شبیه به یادگیری ماشین نظارتشده است، اما الگوریتم آن با استفاده از دادههای نمونه آموزش داده نمیشود. در واقع یادگیری تقویتی یک فرآیند مبتنی بر بازخورد است و با استفاده از آزمون و خطا یاد میگیرد.
در این روش، مؤلفه هوش مصنوعی بهطور خودکار با روش آزمون و خطا و از تجربیات یاد میگیرد و مرتب عملکرد خود را بهبود میدهد. در عمل برای یادگیری با روش تقویتی، ماشین برای هر عمل خوب پاداش و برای هر حرکت اشتباه جریمه میشود. بنابراین، مؤلفه یادگیری تقویتی با انجام اقدامات خوب، روی به حداکثر رساندن پاداش تمرکز میکند. در نتیجه نهایتا دنبالهای از نتایج موفقیتآمیز برای ایجاد بهترین توصیه یا خط مشی برای یک مشکل خاص بهوجود میآید.
بهطور کلی یادگیری تقویتی به دو نوع روش یا الگوریتم تقسیم میشود:
- یادگیری تقویتی مثبت (Positive Reinforcement Learning): این روش روی افزودن یک محرک تقویتکننده مثل پاداش پس از یک رفتار خاص مثبت تمرکز میکند. با این کار قرار است احتمال تکرار این رفتار مثبت در آینده افزایش پیدا کند.
- یادگیری تقویتی منفی (Negative Reinforcement Learning): یادگیری تقویتی منفی روی تقویت یک رفتار خاص تمرکز میکند. رفتاری که از نتیجه منفی جلوگیری خواهد کرد.
یادگیری تقویتی در زمینههای مختلفی مانند نظریه بازی، نظریه اطلاعات و سیستمهای چند عاملی کاربرد دارد. مثلا میتواند به مدلها آموزش دهد تا بازی کنند یا وسایل نقلیه خودران را آموزش دهد تا در شرایط ترافیکی مختلف تصمیمهای درستتری بگیرند و سلامتتر برای رانندگی و حرکت در خیابانها اقدام کنند.
در ماشین لرنینگ از چه الگوریتمهایی استفاده میشود؟
فرقی نمیکند که از کدام روش یادگیری ماشین استفاده میکنید، هر چهار روش نیاز به الگوریتم برای اجرای فرآیند آموزش دارند. تعدادی از الگوریتمهای یادگیری ماشین که بیشتر استفاده میشوند عبارتند از:
۱-الگوریتم شبکههای عصبی (Neural Networks)
این الگوریتمها نحوه عملکرد مغز انسان را با تعداد زیادی گره پردازشی مرتبط شبیهسازی میکنند. شبکههای عصبی در تشخیص الگوها عملکرد بسیاری خوبی دارند و برای کاربردهایی مثل ترجمه زبان طبیعی، تشخیص تصویر، تشخیص یا بازشناسی گفتار (Speech Recognition) و ایجاد تصویر گزینه عالی هستند.
۲-الگوریتم رگرسیون خطی (Linear Regression)
این الگوریتم برای پیشبینی مقادیر عددی بر اساس رابطه خطی بین مقادیر مختلف استفاده میشود. بهعنوان مثال، این تکنیک میتواند برای پیشبینی قیمت خانه بر اساس دادههای تاریخی برای مناطق جغرافیایی مختلف استفاده شود.
۳-الگوریتم رگرسیون لجستیک (Logistic Regression)
این الگوریتم یادگیری نظارتشده برای متغیرهای برچسبگذاریشده پاسخ طبقهای «بله/خیر» پیشبینی میکند. معمولا کاربرد اصلی این الگوریتم در برنامههایی مانند طبقهبندی هرزنامه و کنترل کیفیت در خط تولید است.
۴-الگوریتم خوشهبندی (Clustering)
الگوریتمهای خوشهبندی میتوانند با استفاده از یادگیری بدون نظارت، الگوهای موجود در دادهها را شناسایی و دادههای ورودی را گروهبندی کنند. تکنیک خوشهبندی برای گروهبندی اشیا از پارامترهایی مانند شباهتها یا تفاوتهای بین آنها کمک میگیرد. مثلا میتواند مشتریان را بر اساس محصولاتی که خریداری میکنند گروهبندی کند. الگوریتم K-Means Clustering، Mean-Shift Algorithm، الگوریتم DBSCAN، Principal Component Analysis و Independent Component Analysis نمونههایی از الگوریتمهای خوشهبندی شناختهشده هستند.
۵-درخت تصمیم (Decision Trees)
درخت تصمیم را میتوان هم برای پیشبینی مقادیر عددی (رگرسیون) و هم برای طبقهبندی دادهها به دستهها استفاده کرد. یک درخت تصمیم از یک دنباله انشعاب از تصمیمات مرتبط استفاده میکند. این دنباله میتواند با یک نمودار درختی نمایش داده شود. یکی از مزایای درخت تصمیم این است که بر خلاف جعبه سیاه شبکه عصبی، اعتبارسنجی و ممیزی آن آسان است.
۶-جنگلهای تصادفی (Random Forests)
در یک جنگل تصادفی، الگوریتم یادگیری ماشین یک مقدار یا دسته را با ترکیب نتایج تعدادی درخت تصمیم پیشبینی میکند.
علاوه بر این الگوریتمها، الگوریتمهایی دیگری مثل ماشین بردار پشتیبان (Support Vector Machine | SVM)، دستهبندی بیز ساده (naïve Bayes Classification)، رگرسیون خطی ساده (Simple Linear Regression)، رگرسیون چند متغیره (Multivariate Regression) و رگرسیون لاسو (Lasso Regression) هم در ماشین لرنینگ وجود دارد.
نگاهی به موارد استفاده از ماشین لرنینگ در دنیای واقعی
امروزه با ظهور کلان داده، اینترنت اشیا و محاسبات فراگیر، یادگیری ماشین برای حل مشکلات در بسیاری از زمینهها مانند محاسبات مالی (رتبهبندی اعتبار، معاملات الگوریتمی)، بینایی ماشین (Computer Vision) برای تشخیص چهره، ردیابی حرکت، تشخیص اشیا، زیستشناسی محاسباتی (Computational Biology) مانند توالییابی DNA، تشخیص تومور مغزی، کشف دارو، خودروسازی (Automotive)، هوافضا (Aerospace) و تولید (Manufacturing) شامل تعمیر و نگهداری پیشبینیشده، پردازش زبان طبیعی (Natural Language Processing | NLP) مثل تشخیص صدا (Voice Recognition) استفاده میشود.
شاید موارد استفاده از یادگیری ماشین در دنیای واقعی کمی برایتان گنگ باشد. پس بهتر است چند نمونه از ماشین لرنینگ که احتمالا هر روز با آنها روبرو میشوید را با هم مرور کنیم.
۱-سیستم تشخیص گفتار یا Automatic Speech Recognition (ASR)
از سیستم تشخیص گفتار بیشتر برای تبدیل گفتار به متن استفاده میشود. یعنی این سیستم یک قابلیت یادگیری ماشین است که با کمک پردازش زبان طبیعی (NLP) گفتار انسان را به قالب نوشتاری تبدیل میکند. امکان جستجوی صوتی که روی بسیاری از دستگاههای تلفن همراه وجود دارد یا نرمافزارهایی مثل Siri از تشخیص گفتار در سیستمهای خود استفاده میکنند.
۲-چتباتهای آنلاین
خدمات مشتری و پاسخگویی سریع و کامل به سوالات مشتریها یکی از ابزارهای اصلی برای تبدیل شدن به برند برتر در بازار امروز است. در همین راستا برای خدمترسانی بهتر چتباتهای آنلاین در طول سفر مشتری جایگزین عوامل انسانی شدهاند و بهنوعی تعامل با مشتری در بین وبسایتها و پلتفرمهای شبکههای اجتماعی را تغییر دادهاند. این رباتها به سؤالات متداول در مورد موضوعاتی مانند حملونقل پاسخ میدهند، یا توصیههای شخصی برای خرید محصولات مناسبتر در اختیار کاربران میگذارند.
۳-بینایی ماشین (Computer vision)
بینایی ماشین و فناوری هوش مصنوعی رایانهها را قادر میسازد تا اطلاعات معنیداری را از تصاویر دیجیتال، ویدیوها و سایر ورودیهای بصری به دست بیاورند و براساس این اطلاعات اقدام مناسب را انجام دهند. بینایی ماشین با پشتیبانی از شبکههای عصبی کانولوشنال کار میکند. کاربردهای اصلی این نرمافزارها برچسبگذاری عکس در رسانههای اجتماعی، تصویربرداری رادیولوژی در مراقبتهای بهداشتی و خودروهای خودران در صنعت خودرو است.
بینایی ماشین در شبکههای اجتماعی هم کاربرد مهمی دارد. بهعنوان مثال، ویژگی برچسبگذاری خودکار فیسبوک از تشخیص تصویر برای شناسایی چهره دوست شما و تگ کردن خودکار آنها استفاده میکند. این شبکه اجتماعی از ANN برای شناسایی چهرههای آشنا در لیست مخاطبین کاربران استفاده و برچسبگذاری خودکار را تسهیل میکند.
۴-موتورهای توصیه (Recommendation Engines)
با استفاده از دادههای رفتار مصرف گذشته، الگوریتمهای هوش مصنوعی به کشف روندهای دادهای که میتوانند برای توسعه استراتژیهای فروش متقابل مؤثرتر مورد استفاده قرار گیرند، کمک میکنند. این رویکرد توسط خردهفروشان آنلاین برای ارائه توصیههای مربوط به محصول به مشتریان در طول فرآیند پرداخت استفاده میشود. الگوریتم پیشنهادات Netflix و YouTube یا موتور جستجوی گوگل نمونه شناختهشده موتورهای جستجو هستند. در شبکههای اجتماعی هم این کاربرد ماشین لرنینگ هدایت پلتفرمهای رسانههای اجتماعی و شخصیسازی فیدهای خبری و همچنین ارائه تبلیغات خاص کاربر را ممکن میکند.
وبسایتهای خردهفروشی از یادگیری ماشین برای توصیه اقلام به کاربران خود بر اساس سابقه خرید قبلی آنها استفاده میکنند. معمولا خردهفروشان تکنیکهای ML را برای جمعآوری دادهها، تجزیهوتحلیل آنها و ارائه تجربیات خرید شخصی به مشتریان خود بهکار میبرند. آنها همچنین ML را برای کمپینهای بازاریابی، بهینهسازی قیمت و… نیز پیادهسازی میکنند. مثلا وقتی آیتمهای خرید را در یک فروشگاه آنلاین مثل آمازون مرور میکنید، توصیههای محصولی که در صفحه اصلی میبینید از الگوریتمهای یادگیری ماشینی ناشی میشوند. آمازون از شبکههای عصبی مصنوعی (ANN) برای ارائه توصیههای شخصی و هوشمند مرتبط با مشتریان بر اساس تاریخچه خرید اخیر، نظرات، نشانکها و سایر فعالیتهای آنلاین استفاده میکند.
۵-معاملات خودکار سهام
پلتفرمهای معاملاتی با فرکانس بالا مبتنی بر هوش مصنوعی که برای بهینهسازی سبد سهام طراحی شدهاند، هزاران یا حتی میلیونها معامله را در روز بدون دخالت انسان انجام میدهند. بینشهای بهدست آمده از ML به شناسایی فرصتهای سرمایهگذاری بهتر کمک میکند و به سرمایهگذاران اجازه میدهد تصمیم بگیرند چه زمانی معامله کنند.
۶-تشخیص تقلب
بانکها و سایر موسسات مالی میتوانند از یادگیری ماشین برای شناسایی تراکنشهای مشکوک استفاده کنند. یادگیری تحت نظارت میتواند یک مدل را با استفاده از اطلاعات مربوط به تراکنشهای جعلی شناختهشده به ماشین آموزش دهد. در نتیجه ماشین میتواند با تشخیص ناهنجاریها تراکنشهایی که غیر معمول به نظر میرسند و مستحق بررسی بیشتر هستند را شناسایی کند. مثلا شرکت پیپال از چندین ابزار یادگیری ماشین برای تمایز بین تراکنشهای قانونی و تقلبی بین خریداران و فروشندگان استفاده میکند.
درضمن برای ردگیری تلاشهای ورود به اکانتهای کاربری شبکههای اجتماعی یا ایمیلهای هرزنامه هم از یادگیری ماشین استفاده میشود.
۷-مراقبتهای بهداشتی و تشخیص پزشکی
برنامههای یادگیری ماشین را میتوان برای بررسی تصاویر پزشکی یا سایر اطلاعات و جستجوی نشانگرهای خاص بیماری آموزش داد. مانند ابزاری که میتواند خطر سرطان را براساس ماموگرافی پیشبینی کند. علاوهبراین، این فناوریها به پزشکان در تجزیه و تحلیل روندها یا نشانهگذاری رویدادهایی که ممکن است به بهبود تشخیص و درمان بیمار یاری برساند، کمک میکنند. الگوریتمهای ML حتی به متخصصان پزشکی اجازه میدهند تا طول عمر بیمار مبتلا به یک بیماری کشنده را با دقت فزاینده پیشبینی کنند.
نرمافزارهای مدیریت تقویم پریود و حتی ساعتهای سلامت هوشمند که دادههای سلامتی کاربران را برای ارزیابی سلامت آنها در زمانهای مشخص جمعآوری میکنند هم همگی بخشی از کاربردهای روزمره ماشین لرنینگ محسوب میشوند.
۸-صنعت حملونقل عمومی و سفرهای شهری
یادگیری ماشین نقشی پررنگی در تحولات صنعت سفرهای درونشهری و حملونقل دارد. سواریهای ارائهشده توسط Uber ،Ola یا اسنپ و تپسی در ایران متکی به پشتوانه یادگیری ماشین هستند.
قیمتگذاری پویا در پلتفرمهای تاکسیهای آنلاین همگی توسط ماشین لرنینگ مدیریت میشوند. برای مثال اوبر برای قیمتگذاری از یک مدل یادگیری ماشینی بهنام «Geosurge» برای مدیریت پارامترهای قیمتگذاری پویا استفاده میکند. این مدلسازی روی پیشبینی الگوهای ترافیک، عرضه و تقاضا و… تمرکز دارد. مثلا اگر برای شرکت در یک جلسه دیرتان شده و نیاز به سفارش سفر با تپسی یا اسنپ در یک منطقه شلوغ دارید، با زدن دکمه عجله دارم مدل قیمتگذاری پویا شروع میشود و میتوانید سریعتر سوار ماشین شوید، اما باید بیشتر از کرایه معمولی بپردازید.
پلتفرمهای تاکسی اینترنتی همچنین از یادگیری ماشین برای تجزیهوتحلیل نظرات کاربران استفاده میکنند. نظرات کاربران درباره هر راننده از طریق تجزیهوتحلیل نمرات مثبت یا منفی طبقهبندی میشوند.
علاوهبراینها، در ماشینهای خودران یا اتوماتیک هم از یادگیری ماشین استفاده میشود. واقعیت این است که بسیاری از فناوریهای پشت خودروهای خودران مبتنی بر یادگیری ماشین، به ویژه یادگیری عمیق هستند.
چالشهای پیش روی یادگیری ماشین چیست؟
فناوری یادگیری ماشین و هوش مصنوعی همانقدر که زندگی ما را آسانتر کرده، پیادهسازی آن در مشاغل مختلف، نگرانیهای اخلاقی زیادی را هم ایجاد کرده است. مهمترین چالشها و محدودیتهای اخلاقی که ماشین لرنینگ برای انسان بهوجود آورده را میتوان بهشکل زیر گروهبندی کرد:
۱-تکینگی تکنولوژیک (Technological singularity)
منظور از تکینگی تکنولوژیک هوش مصنوعی قوی یا ابر هوش است. شاید پیشی گرفتن هوش مصنوعی از هوش انسانی و فیلمها و سریالها یک ایده داستانی جذاب باشد، اما بسیاری از محققان هنوز نگران این موضوع نیستند که هوش مصنوعی در آینده نزدیک از هوش انسانی پیشی بگیرد. با این حال باید سوالات مهمی را درباره پیشرفت و توسعه این هوش پاسخ دهیم. مثلا نمیتوانیم صددرصد تضمین کنیم که یک ماشین بدون راننده هرگز تصادف نمیکند، اما چه کسی در این شرایط مسئول خواهد بود؟ اینها انواع بحثهای اخلاقی هستند که باید در کنار توسعه فناوری جدید و خلاقانه هوش مصنوعی برایشان پاسخی پیدا شود.
۲-تاثیر هوش مصنوعی بر مشاغل
یکی از تصورات رایج درباره آینده هوش مصنوعی این است که باعث از دست دادن شغل بسیاری از افراد میشود. این موضوع یک نگرانی اخلاقی جدی است که باید درباره آن فکر کنیم. واقعیت این است که هر فناوری جدیدی میتواند روی تقاضای بازار برای نقشهای شغلی خاص تاثیر بگذارد. مثلا در صنعت خودرو بسیاری از تولیدکنندگان، از جمله جنرال موتورز، روی تولید خودروهای الکتریکی تمرکز کردهاند. در واقع نیاز صنعت به انرژی از بین نرفته، اما منبع انرژی در حال تغییر از مصرف سوخت به برق است.
به همین ترتیب، هوش مصنوعی تقاضا برای مشاغل را تغییر میدهد. در واقع باز هم باید افرادی وجود داشته باشند که مدیریت سیستمهای هوش مصنوعی را برعهده بگیرند. یا باید افرادی وجود داشته باشند که مشکلات پیچیدهتری را در صنایعی که احتمالا تحت تأثیر تغییرات تقاضای شغلی قرار میگیرند (مانند خدمات مشتری)، حل کنند. تأثیر هوش مصنوعی و یادگیری ماشین بر بازار کار، کمک به افراد برای انتقال به نقشهای جدید مورد تقاضا احتمالا بزرگترین چالش پیش روی این حوزه است.
۳-حریم خصوصی
وقتی پای دادهها و مخصوصا کلاندادهها در میان باشد موضوع حریم خصوصی، حفاظت از دادهها و امنیت دادهها یک بحث جدی خواهد بود. این نگرانیها باعث شده قوانین و سیاستهای جدیدی در بحث تکنولوژی اعمال شود. مثلا در اتحادیه اروپا و منطقه اقتصادی اروپا از سال ۲۰۱۶، قانون GDPR برای محافظت از دادههای شخصی افراد اجرا میشود تا به افراد کنترل بیشتری بر دادههای خود دهد.
قوانین جدید شرکتها را وادار کرده است که در نحوه ذخیره و استفاده از اطلاعات شخصی قابل شناسایی (PII) تجدید نظر کنند. در نتیجه، سرمایهگذاری در امنیت به یک اولویت فزاینده برای کسبوکارها تبدیل شده است. حذف هرگونه آسیبپذیری و ایجاد فرصتهایی برای نظارت دقیقتر، جلوگیری از هک و حملات سایبری حرف اول را در این حوزه میزند.
۴-تعصب و تبعیض
نمونههایی از تعصب و تبعیض در تعدادی از سیستمهای یادگیری ماشین، سوالات اخلاقی زیادی را در مورد استفاده از هوش مصنوعی ایجاد کرده است.
واقعیت این است که ماشینها توسط انسانها آموزش داده میشوند و سوگیریهای انسانی میتوانند در الگوریتمها گنجانده شوند. اگر اطلاعات مغرضانه یا دادههایی که نابرابریهای موجود را منعکس میکنند به یک برنامه یادگیری ماشین داده شوند، برنامه یاد میگیرد که این تبعیض را تکرار کند و باعث تداوم تبعیض خواهد شد. چگونه میتوانیم زمانی که دادههای آموزشی ماشین ممکن است توسط فرآیندهای انسانی مغرضانه تولید شوند حقوق انسانی را در برابر تعصب و تبعیض محافظت کنیم؟
تعصب و تبعیض فقط به مواردی مثل عملکرد منابع انسانی محدود نمیشود. از برنامههای کاربردی نرمافزار تشخیص چهره گرفته تا الگوریتمهای رسانههای اجتماعی همگی میتواند باعث این چالشهای اخلاقی شوند.
مثلا IBM برای محصولات تشخیص و تجزیهوتحلیل چهره خود شرایطی دارد و میگوید استفاده از هر فناوری تشخیص چهره ارائهشده توسط فروشندگان این مجموعه، برای نظارت انبوه، ردگیری نژادی پروفایلها، نقض حقوق و آزادیهای اولیه بشر، یا هر هدفی که با ارزشهای برابری انسانی سازگار نیست را نمیپذیرد.
۵-مسئوليت قانونی
از آنجایی که قانون قابلتوجهی برای تنظیم شیوههای اجرای هوش مصنوعی تصویب نشده، هیچ مکانیسم اجرایی واقعی هم برای اطمینان از اجرای هوش مصنوعی اخلاقی وجود ندارد. تنها انگیزه فعلی برای اخلاقی بودن شرکتها، پیامدهای منفی یک سیستم هوش مصنوعی غیراخلاقی در افکار عمومی است. برای پر کردن این شکاف، تعیین چارچوبهای اخلاقی در قانون بهعنوان بخشی از همکاری بین اخلاقشناسان و محققان برای کنترل ساخت و توزیع مدلهای هوش مصنوعی در جامعه نیاز خواهد بود.
جمعبندی
کامپیوترها هم میتوانند مثل انسان یاد بگیرند. یادگیری ماشین براساس دادههای برچسبگذاریشده یا برچسبگذارینشده مدیریت و برنامهریزی میشود. یعنی کامپیوتر باتوجه به دادههایی که در الگوریتمهای مشخصی برایش خوانده میشود میتواند آموزش ببیند و خروجیهای دقیقی تولید کنند. ماشین لرنینگ کمک میکند تا شرکتها و کمپانیهای مختلف تصمیمات آگاهانهای برای سادهسازی عملیات تجاری خود بگیرند. چنین تصمیمات مبتنی بر داده به تمام صنایع، از تولید، خردهفروشی، مراقبتهای بهداشتی، انرژی و خدمات مالی کمک میکند تا عملیات فعلی خود را بهینه کنند و در عین حال بتوانند بهفکر کاهش حجم کاری نیروهای انسانی خود باشند.
اگر میخواهید اطلاعات دقیقتری درباره الگوریتمهای مختلف یادگیری ماشین، تفاوت ماشین لرنینگ و دیپ لرنینگ، شبکههای عصبی مصنوعی و کلان دیتا داشته باشید حتما مجموعه پستهای این مجموعه از مقالههای رهنما کالج را دنبال کنید. همچنین برای یادگیری عملی ماشین لرنینگ میتوانید در بوت کمپ آموزش ماشین لرنینگ رهنما کالج شرکت کنید.