
این روزها یادگیری ماشین قرار ملاقاتهای ما را برنامهریزی میکند و اخبار را اعلام میکند، آهنگ و فیلم و سریال به ما پیشنهاد میدهد و پخش میکند و حتی محتواهای صوتی را به متنهای نوشتاری تبدیل میکند. تمام این سیستمهای هوشمند براساس الگوریتمهای یادگیری ماشین کار میکنند. انواع مختلفی از الگوریتمهای یادگیری ماشین وجود دارد که به هوشمندتر شدن و شخصیتر شدن نرمافزارها و اپلیکیشنها کمک میکنند. از بازی شطرنج گرفته تا انجام جراحیها و… همه توسط الگوریتمهای ماشین لرنینگ هدایت و انجام میشوند.
اگر میخواهید یادگیری ماشین را شروع کنید یا در این زمینه کار میکنید، یادگیری الگوریتمهای ماشین لرنینگ برایتان حیاتی است و میتواند مهارتهای شما را بهعنوان مهندس یادگیری ماشین افزایش دهد. در این مقاله الگوریتمهای پراستفاده و محبوب یادگیری ماشین همراه با کاربردهای آنها در دنیای واقعی معرفی شدهاند.
منظور از الگوریتم یادگیری ماشین چیست؟
الگوریتم یادگیری ماشین یک کد (ریاضی یا برنامهنویسی) است که به مهندسان ماشین لرنینگ اجازه میدهد مجموعههای داده پیچیده و بزرگ را مطالعه، تجزیهوتحلیل، درک و کاوش کنند. هر الگوریتم یک سری دستورالعمل خاص را دنبال میکند تا با یادگیری، ایجاد و کشف الگوهای موجود در دادهها، به هدف پیشبینی یا طبقهبندی اطلاعات برسد. در یک جمله الگوریتمهای ماشین لرنینگ مدلهای ریاضی هستند که از دادهها یاد میگیرند و الگوهای تعبیهشده در آنها را باز میکنند.
بهعبارت دیگر الگوریتمهای یادگیری ماشین قوانین و فرآیندهایی را مشخص میکنند که یک سیستم (ماشین) باید برای حل یک مشکل یا مسئله خاص در نظر داشته باشد. این الگوریتمها دادهها را برای پیشبینی نتیجه در محدوده از پیشتعیینشده تجزیهوتحلیل و شبیهسازی میکنند. همچنین با وارد شدن دادههای جدید به این الگوریتمها، آنها بر اساس بازخورد عملکرد قبلی در پیشبینی نتایج، یاد میگیرند، بهینه میشوند و بهبود پیدا میکنند. یعنی الگوریتمهای ماشین لرنینگ با هر تکرار «هوشمندتر» میشوند.
انواع الگوریتمهای یادگیری ماشین
الگوریتمهای یادگیری ماشین با توجه به نوع تکنیک یادگیری به چهار گروه تقسیم میشوند: تحت نظارت یا نظارتشده، نیمه نظارتی، نظارتنشده یا بدون نظارت و یادگیری تقویتی.
۱-الگوریتم یادگیری نظارت شده (Supervised machine learning)
الگوریتمهای یادگیری نظارتشده از مجموعه دادههای برچسبگذاریشده برای پیشبینی استفاده میکنند. این تکنیک یادگیری بیشتر زمانی مفید است که نوع نتیجهای که قصد دارید بهدست بیاوریم را بدانیم.
مثلا یک مجموعه داده از مقادیر بارانی که در یک فصل در طول ۲۰۰ سال گذشته در یک منطقه جغرافیایی رخ داده است در اختیار داریم. هدف از برنامهریزی ماشین این است که باران مورد انتظار در این فصل خاص برای ده سال آینده را برایمان پیشبینی کند. اینجا، نتیجهگیری بر اساس برچسبهای موجود در مجموعه داده اصلی، یعنی بارندگی، منطقه جغرافیایی، فصل و سال بهدست میآید.
۲-الگوریتم یادگیری بدون نظارت (Unsupervised machine learning)
الگوریتمهای یادگیری بدون نظارت از دادههای بدون برچسب استفاده میکنند. این الگوریتم یادگیری دادههای بدون برچسب را با دستهبندی دادهها یا بیان نوع، شکل یا ساختار آنها برچسبگذاری میکند. کاربرد اصلی این تکنیک زمانی است که نوع نتیجه ناشناخته است.
برای مثال، وقتی مجموعه دادهای از کاربران فیسبوک دارید و میخواهید کاربرانی را که به کمپینهای تبلیغاتی مشابه فیسبوک تمایل دارند (براساس لایکها) طبقهبندی کنید باید از این تکنیک کمک بگیرید. اینجا مجموعه دادههای اولیه بدون برچسب هستند. با این حال، نتیجه دارای برچسبهایی خواهد بود. زیرا الگوریتم یادگیری شباهتهایی را بین نقاط داده در حین طبقهبندی کاربران پیدا میکند.
۳-الگوریتم یادگیری نیمه نظارتی (Semi-supervised learning)
الگوریتمهای یادگیری نیمهنظارتی در واقع تکنیکهای نظارتشده و نظارتنشده برای یادگیری ماشین را با هم ترکیب میکنند. یعنی بسته به نیاز پروژه در بخشهایی از تکنیک از دادههای برچسبدار و در بخشی دیگر از دادههای بدون برچسب استفاده میشود. هدف این الگوریتمها در اصل دستهبندی دادههای بدون برچسب بر اساس اطلاعات بهدست آمده از دادههای برچسبدار است.
طبقهبندی محتوای وب یک نمونه استفاده از این تکنیک است. طبقهبندی و رتبهبندی محتوای موجود در اینترنت یک کار زمانبر است که نیاز به منابع فشرده دارد. یعنی جدا از الگوریتمهای هوش مصنوعی، برای سازماندهی میلیاردها صفحه وب بهصورت آنلاین، به منابع انسانی هم نیاز خواهد بود. در چنین مواردی، مدلهای SSL میتوانند نقش مهمی در انجام کارها به نحو احسن ایفا کنند.
۴-الگوریتم یادگیری تقویتی (Reinforcement machine learning)
الگوریتمهای یادگیری تقویتی از نتیجه دادههای بهدستآمده هر مرحله بهعنوان معیاری برای تصمیمگیری در مرحله اقدام بعدی استفاده میکنند. این الگوریتمها از نتایج قبلی یاد میگیرند، پس از هر مرحله بازخورد دریافت میکنند و سپس تصمیم میگیرند که آیا مرحله بعدی را ادامه دهند یا خیر. در این تکنیک سیستم (ماشین) یاد میگیرد که آیا در فرآیند انتخاب درست، اشتباه یا خنثی عمل کرده است. سیستمهای خودکار معمولا از یادگیری تقویتی استفاده میکنند، زیرا برای تصمیمگیری با حداقل دخالت انسان طراحی شدهاند.
بهعنوان مثال، برای آزمایش و بررسی اینکه یک خودروی خودران از قوانین راهنمایی و رانندگی پیروی کند و ایمنی در جادهها را تضمین کند از تکنیک یادگیری تقویتی استفاده میشود. با این روش وسیله نقلیه از طریق تجربه و تاکتیکهای تقویتی یاد میگیرد که قوانین راهنمایی و رانندگی را رعایت کند.
بهعبارت دیگر الگوریتم یادگیری تقویتی تضمین میکند که خودرو از قوانین راهنمایی و رانندگی برای ماندن در یک لاین پیروی میکند، از محدودیتهای سرعت عبور نمیکند و از برخورد با عابران پیاده یا حیوانات در جاده جلوگیری میکند.
۱۲ الگوریتم ماشین لرنینگ که بیشترین استفاده را دارند
انواع مختلفی از الگوریتمهای یادگیری ماشین برای کمک به حل مسائل پیچیده دنیای واقعی طراحی شدهاند. هرکدام از این الگوریتمها برای موضوعات و حوزههای خاصی استفاده میشوند و مدل و تکنیک یادگیری ماشین مخصوص بهخودشان را دارند. بسته به نوع الگوریتم نیز، مدلهای یادگیری ماشین از پارامترهای مختلفی مانند پارامتر گاما، max_depth، n_neighbors و سایر پارامترها برای تجزیه و تحلیل دادهها و تولید نتایج دقیق استفاده میکنند. این پارامترها نتیجه دادههای آموزشی هستند که مجموعه داده بزرگتری را نشان میدهند.
در ادامه لیستی از ۱۲ الگوریتم برتر رایج یادگیری ماشین (ML) را با هم بررسی میکنیم:
۱-الگوریتم رگرسیون خطی (Linear Regression)
برای درک عملکرد رگرسیون خطی تصور کنید که چگونه میتوانید کندههای چوب تصادفی را بهترتیب وزن آنها مرتب کنید. کار پیچیده و زمانگیری است. مخصوصا که شما نمیتوانید هر کنده چوب را جداگانه وزن کنید. یعنی باید وزن آن را فقط با نگاه کردن به ارتفاع و دور چوب (تحلیل بصری) و مرتب کردن آنها با استفاده از ترکیبی از این پارامترهای قابل مشاهده حدس بزنید. پس باید از ترکیبی از متغیرهای قابل مشاهده برای چیدمان نهایی کندههای چوب استفاده شود. الگوریتم رگرسیون خطی رابطهای بین ورودی (x) و متغیر خروجی (y) بهدست میآورد که به آن متغیرهای مستقل و وابسته نیز گفته میشود.
در این فرآیند بین متغیرهای مستقل و وابسته با برازش آنها در یک خط رابطه برقرار میشود. این خط به خط رگرسیون معروف است و با یک معادله خطی Y= a *X + b نشان داده میشود. در این معادله:
- Y – متغیر وابسته
- a – شیب
- X – متغیر مستقل
- b – مقدار ثابت رهگیری یا نقطهای که خط جداکننده محور Yها را قطع میکند
ضرایب a و b با به حداقل رساندن مجذور اختلاف فاصله بین نقاط داده و خط رگرسیون بهدست میآیند.
بهطور کلی هدف از رگرسیون خطی پیدا کردن بهترین خط برازش است که رابطه بین متغیرهای y و x را روشن میکند. این الگوریتمها محبوبترین گزینه برای پیشبینی مقادیر، شناسایی شباهتها و کشف الگوهای دادههای غیرعادی است. البته رگرسیون خطی چندمتغیره هم وجود دارد که در آن تعداد متغیرهای مستقل بیشتر از یک است.
۲-الگوریتم رگرسیون لجستیک (Logistic Regression)
رگرسیون لجستیک برای تخمین مقادیر گسسته (معمولا مقادیر باینری و دوگانه) از مجموعهای از متغیرهای مستقل استفاده میشود. در واقع متغیر وابسته در رگرسیون لجستیک از نوع باینری (دوگانه) است. این نوع تحلیل رگرسیون دادهها را توصیف میکند و رابطه بین یک متغیر دوگانه و یک یا چند متغیر مستقل را توضیح میدهد.
الگوریتم رگرسیون لجستیک معمولا در تجزیهوتحلیل پیشگویانه استفاده میشود و بهکمک آن دادههای مربوط به احتمال رویداد را برای یک تابع لوجیت پیشبینی میکنند. بنابراین به آن رگرسیون لاجیت یا رگرسیون لوجیت نیز گفته میشود.
مثلا از رگرسیون لجستیک میتوان برای پیشبینی اینکه آیا یک تیم خاص (1) جام جهانی فوتبال ۲۰۲۶ را برنده میشود یا خیر (0)، یا اینکه بهدلیل افزایش موارد COVID-19 قرنطینه (1) اعمال میشود یا خیر (0) استفاده کرد. بنابراین، نتایج باینری رگرسیون لجستیک تصمیمگیری سریعتر را تسهیل میکند، زیرا فقط باید یکی از دو گزینه را انتخاب کنید.
از نظر ریاضی هم رگرسیون لجستیک با معادله زیر نشان داده میشود:
y = e^(b0 + b1*x) / (1 + e^(b0 + b1*x))
در این معادله، x = مقدار ورودی، y = خروجی پیشبینیشده، b0 = بایاس یا عبارت رهگیری و b1 = ضریب ورودی (x) است.
۳-الگوریتم درخت تصمیم (Decision Tree)
الگوریتم درخت تصمیم در یادگیری ماشین یکی از محبوبترین الگوریتمهایی است که امروزه مورد استفاده قرار میگیرد. این الگوریتم یک مدل یادگیری نظارتشده است و کاربرد اصلیاش طبقهبندی مسائل است. درخت با یک گره ریشه (گره تصمیم) شروع میشود و سپس به گرههای فرعی منشعب میشود که نتایج بالقوه را نشان میدهد. هر نتیجه میتواند گرههای فرزندی را ایجاد کند که میتواند احتمالات دیگری را باز کند. در نهایت الگوریتم یک ساختار درختمانند ایجاد میکند که برای طبقهبندی مسائل استفاده میشود.
الگوریتمهای درخت تصمیم بهطور بالقوه میتوانند بهترین گزینه را بر اساس یک ساختار ریاضی پیشبینی کنند و همچنین هنگام طوفان فکری روی یک تصمیم خاص مفید باشند. در ضمن الگوریتم درخت تصمیم در طبقهبندی متغیرهای وابسته مقولهای و پیوسته به خوبی عمل میکند. همچنین میتواند جمعیت را به دو یا چند مجموعه همگن بر اساس مهمترین ویژگیها/ متغیرهای مستقل تقسیم کند. پس با یک درخت تصمیم، میتوانید نقشه نتایج بالقوه را برای یک سری تصمیمات تجسم کنید. برای همین هم شرکتها و کسبوکارهای مختلف برای اینکه نتایج احتمالی را با هم مقایسه کنند و سپس بر اساس پارامترهایی مانند مزایا و احتمالاتی که برای آنها مفید است، تصمیمی مستقیم بگیرند معمولا از این الگوریتم یادگیری استفاده میکنند.
بهعنوان مثال، درخت تصمیم زیر را در نظر بگیرید که به نهایی کردن یک برنامه در آخر هفته بر اساس پیشبینی آبوهوا کمک میکند.
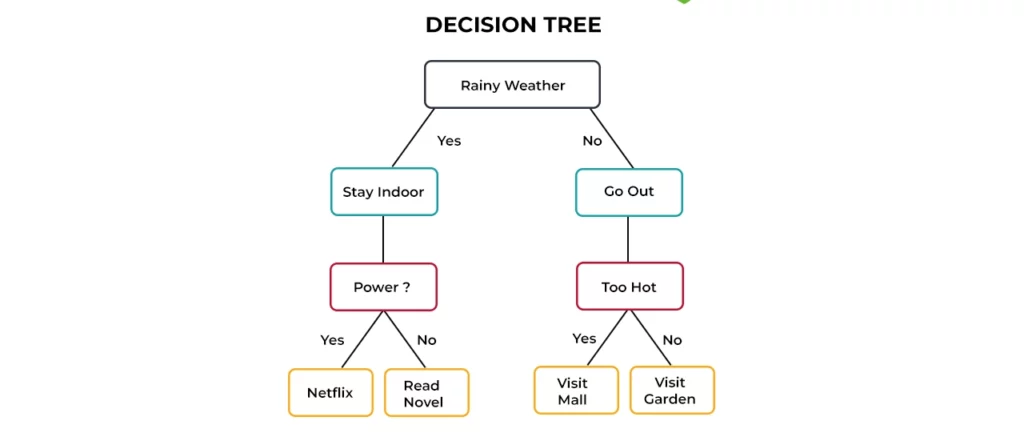
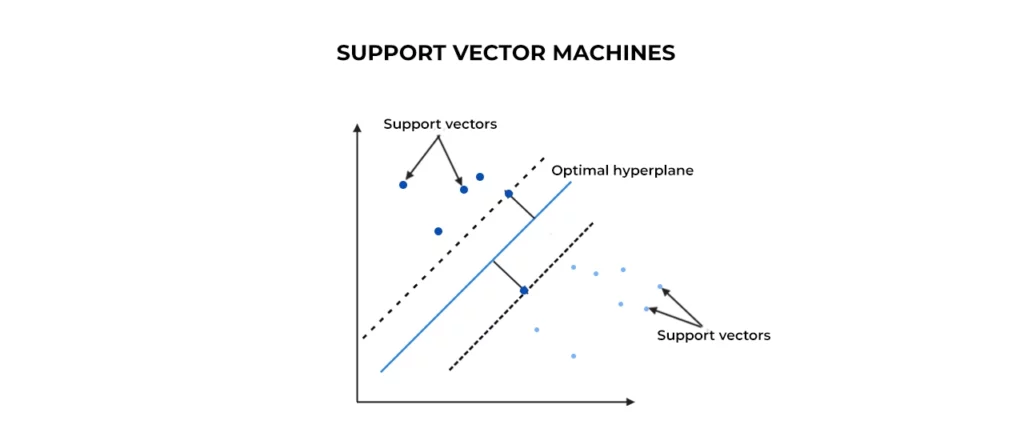
۴-الگوریتم ماشین برداری پشتیبانی (Support Vector Machine)
الگوریتم SVM یکی از انواع الگوریتم طبقهبندی است که در آن دادههای خام بهصورت نقاط در یک فضای n بعدی رسم میشود (n تعداد ویژگیهایی است که دارید). سپس ارزش هر ویژگی به یک مختصات خاص گره میخورد تا طبقهبندی دادهها را آسان کند. در این تکنیک از خطوطی بهنام طبقهبندیکننده برای تقسیم دادهها و رسم آنها بر روی یک نمودار استفاده میشود. به زبان ساده، الگوریتمهای SVM مختصات مشاهدات فردی را نشان میدهند.
معمولا کاربرد اصلی الگوریتم ماشین بردار پشتیبان برای انجام وظایف طبقهبندی و رگرسیون است و یکی از محبوبترین تکنیکهای طبقهبندی در یادگیری ماشین هستند. مثلا در برنامههایی مانند طبقهبندی دادهها، طبقهبندی حالات چهره، طبقهبندی متن، تشخیص استگانوگرافی در تصاویر دیجیتال، تشخیص گفتار و موارد دیگر از این الگوریتم استفاده میشود.
۵-الگوریتم بیز ساده (Naive Bayes Algorithm)
الگوریتم Naive Bayes یک الگوریتم یادگیری ماشین احتمالی است که بر اساس مدل احتمال بیزی کار میکند. فرض اساسی الگوریتم این است که ویژگیهای مورد بررسی مستقل از یکدیگر هستند و تغییر در مقدار یکی بر ارزش دیگری تأثیر نمیگذارد. حتی اگر این ویژگیها به یکدیگر مرتبط باشند، طبقهبندیکننده Naive Bayes در هنگام محاسبه احتمال یک نتیجه خاص، همه این ویژگیها را بهطور مستقل در نظر میگیرد.
بهعنوان مثال، اگر یک توپ را در نظر بگیریم و منظورمان یک توپ کریکت، با رنگ قرمز، شکل هندسی گرد، قطر ۷.۱-۷.۲۶ سانتیمتر و جرم ۱۵۶-۱۶۳ گرم باشد، برای الگوریتم بیز ساده اگرچه همه این ویژگیها میتوانند به یکدیگر وابسته باشند، اما هر کدام بهطور جداگانه نیز برای تشخیص و طبقهبندی توپ کریکت کمک میکند.
اصلیترین کاربرد الگوریتم بیز حل مشکلات طبقهبندی است و حتی گاهی از روشهای طبقهبندی بسیار پیچیده هم بهتر عمل میکند. مثلا الگوریتم بیز ساده یک گزینه عالی برای پیشبینیهای زمان واقعی محسوب میشود. دیگر کاربردهای مهم این الگوریتم فیلتر کردن هرزنامه، تحلیل و پیشبینی احساسات، طبقهبندی اسناد و موارد دیگر است.
خبر خوب اینکه توسعه و پیادهسازی یک مدل الگوریتم بیز ساده کار سخت و پیچیدهای نیست و روی مجموعه دادههای بزرگ هم بهخوبی کار میکند.
برای نمایش ریاضی الگوریتم بیز از فرمول و معادله زیر استفاده میشود:
P (X|Y) = (P (Y|X) x P (X)) /P (Y)
در این فرمول X، Y = رویدادهای احتمالی، P (X) = احتمال درست بودن X و P(X|Y) = احتمال مشروط بودن X در حالت Y درست خواهد بود.
۶-الگوریتم کی-نزدیکترین همسایه (K- Nearest Neighbors)
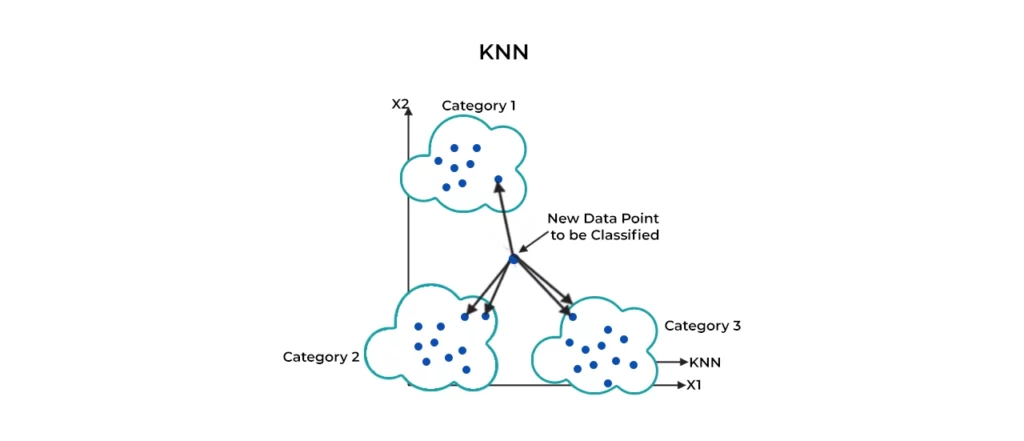
الگوریتم KNN یک الگوریتم ساده است که همه موارد موجود را ذخیره میکند و هر مورد جدید را با کسب اکثریت آرای k همسایههای خود طبقهبندی میکند. این طبقهبندی بر اساس امتیاز شباهت موارد استفاده اخیر با موارد موجود انجام میشود. سپس مورد به کلاسی که بیشترین اشتراک را با آن دارد، اختصاص پیدا میکند. این اندازهگیریها را یک تابع فاصله انجام میدهد.
در واقع KNN یک الگوریتم یادگیری ماشینی نظارت شده است. یعنی در هر مرحله و با تکرار برچسبزنی به دادهها یاد میگیرد و در نهایت طبقهبندی بر اساس رای اکثریت همسایه انجام میشود. درک این الگوریتم با یک مثال ساده از زندگی واقعی چندان سخت نیست. مثلا اگر شما اطلاعاتی در مورد فرد خاصی نیاز دارید، منطقی است که با دوستان و همکاران او صحبت کنید!
البته قبل از انتخاب الگوریتم KNN حتما موارد زیر را در نظر داشته باشید:
- KNN از نظر محاسباتی گران است.
- متغیرها باید نرمالسازی شوند، درغیر این صورت متغیرهای محدوده بالاتر میتوانند باعث سوگیری الگوریتم شوند.
- دادههای این الگوریتم هنوز نیاز به پیش پردازش دارند.
کاربردهای واقعی الگوریتمهای KNN در یادگیری ماشین شامل تشخیص چهره، متنکاوی و سیستمهای توصیه مانند پیشنهادهای آمازون، نتفلیکس و یوتیوب میشود.
۷-الگوریتم K-Means
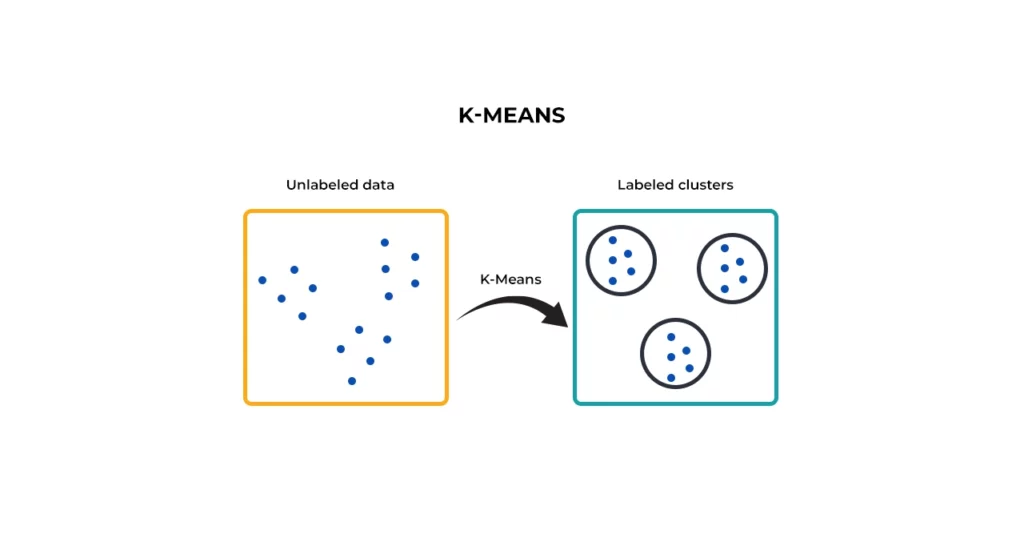
الگوریتم K-Means یک الگوریتم یادگیری ماشینی بدون نظارت مبتنی بر فاصله است که کار خوشهبندی دادهها را انجام میدهد. در این الگوریتم، شما مجموعه دادهها را به خوشههایی بهنام خوشههای K طبقهبندی میکنید که در آن نقاط داده در یک مجموعه همگن باقی مانده و نقاط داده از دو خوشه مختلف ناهمگن میمانند.
اما خوشههای تشکیلشده در الگوریتم K-Means چگونه و بر چه اساسی تشکیل میشوند؟ این الگوریتم براساس قواعد زیر برای هر مجموعه دادهها، خوشهها را مشخص میکند:
- مقداردهی اولیه: الگوریتم برای هر خوشه k تعداد نقطههایی مشخص به نام مرکز را انتخاب میکند.
- تشخیص نزدیکترین اشیا به مرکز: هر نقطه داده یک خوشه با نزدیکترین مرکزها، یعنی خوشههای K تشکیل میدهد.
- بهروزرسانی مرکز: مرکزهای جدید بر اساس خوشههای موجود ایجاد میشوند و دوباره نزدیکترین فاصله برای هر نقطه داده بر اساس مرکزهای جدید مشخص میشود.
- تکرار: این فرآیند تا زمانی که مرکزها (سانتروئیدها) تغییر نکنند تکرار میشود.
الگوریتم خوشهبندی K-Means بیشتر در برنامههایی مانند طبقهبندی کاربران فیسبوک براساس لایکها و اشتراکگذاریها، طبقهبندی اسناد، تقسیمبندی مشتریانی که محصولات تجارت الکترونیک مشابه را خریداری میکنند و… کاربرد دارد.
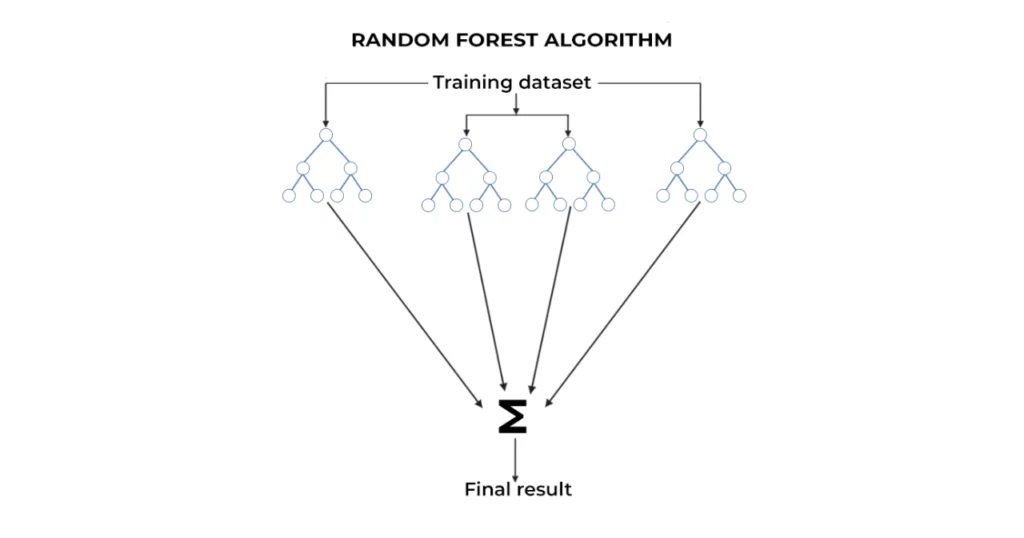
۸-الگوریتم جنگل تصادفی (Random Forest)
الگوریتمهای جنگل تصادفی از درختهای تصمیم چندگانه برای رسیدگی به مشکلات طبقهبندی و رگرسیون استفاده میکنند. این الگوریتم یک مدل یادگیری ماشین نظارتشده است که در آن درختهای تصمیمگیری مختلف روی نمونههای مختلف در طول آموزش ساخته میشوند.
بهعبارت دیگر در الگوریتم جنگل تصادفی برای طبقهبندی یک شی جدید بر اساس ویژگیهای آن، هر بار یک درخت طبقهبندی میشود و درختان دیگر به آن طبقهبندی رای میدهند. در نهایت جنگل طبقهبندیای را انتخاب میکند که بیشترین رای را در بین همه درختان تصمیم داشته باشد.
بهطور کلی در الگوریتم جنگل تصادفی هر درخت براساس قواعد زیر تشکیل میشود:
- نمونههای داده تصادفی از یک مجموعه داده مشخص انتخاب میشوند.
- برای هر نمونه داده یک درخت تصمیم ساخته و نتیجه پیشبینی هر درخت تصمیم مشخص میشود. مثلا اگر M متغیرهای ورودی وجود داشته باشد، یک عدد m<<M مشخص میشود بهطوری که در هر گره، m متغیر بهطور تصادفی از M انتخاب میشود و بهترین تقسیم بر روی این m برای تقسیم گره استفاده میشود. مقدار m در طول این فرآیند ثابت میماند.
- برای هر نتیجه مورد انتظار رایگیری انجام میشود.
- نتیجه پیشبینی نهایی بر اساس بالاترین نتیجه پیشبینی رای دادهشده انتخاب خواهد شد.
الگوریتمهای جنگل تصادفی به تخمین دادههای از دست رفته کمک میکنند و در شرایطی که بخش بزرگی از دادهها را در اختیار نداریم همچنان دقت نتایج را بالا نگه میدارند. به همین دلیل نیز این الگوریتمها یک گزینه عالی برای مواردی مثل امور مالی، تجارت الکترونیک (موتورهای پیشنهاد)، زیستشناسی محاسباتی (طبقهبندی ژن، کشف نشانگرهای زیستی) و… هستند.
۹-الگوریتم شبکههای عصبی مصنوعی (Artificial Neural Networks)
شبکههای عصبی مصنوعی (ANN) الگوریتمهای یادگیری ماشینی هستند که از مغز انسان (رفتار و ارتباطات عصبی) برای حل مشکلات پیچیده تقلید میکنند. یک الگوریتم ANN معمولا سه یا چند لایه به هم پیوسته در مدل محاسباتی خود دارد که دادههای ورودی را پردازش میکنند.
اولین لایه، لایه ورودی یا نورونهایی است که دادههای ورودی را به لایههای عمیقتر ارسال میکند. لایه دوم، لایه پنهان نام دارد. اجزای این لایه با انجام یک سری تبدیل دادهها، اطلاعات دریافتی از طریق لایههای مختلف قبلی را تغییر میدهد. به این لایه، لایه عصبی هم میگویند. لایه سوم هم لایه خروجی است که دادههای خروجی نهایی را برای حل مشکل ارسال میکند.
الگوریتمهای ANN در خانههای هوشمند و دستگاههای اتوماسیون خانگی مانند قفل درب، ترموستات، بلندگوهای (اسپیکرها) هوشمند، چراغهای هوشمند و… استفاده میشوند. الگوریتمها همچنین در زمینه دید محاسباتی، به ویژه در سیستمهای تشخیص چهره و وسایل نقلیه خودران هم کاربرد دارد.
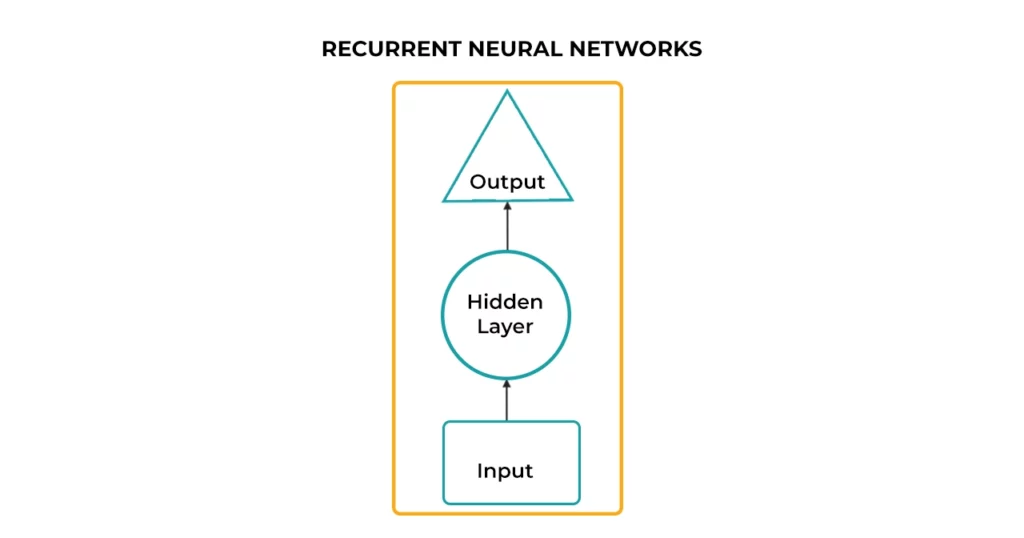
۱۰-الگوریتم شبکه عصبی مکرر یا شبکه عصبی بازگشتی (Neural Networks Recurrent)
شبکههای عصبی مکرر نوع خاصی از ANN هستند که دادههای متوالی را پردازش میکنند. در این الگوریتم، نتیجه مرحله قبل بهعنوان ورودی مرحله فعلی استفاده میشود. این کار از طریق حافظه پنهانی که اطلاعات مربوط به یک دنباله داده را بهخاطر میآورد انجام میشود. یعنی این مدل الگوریتم بهعنوان حافظهای عمل میکند که اطلاعات مربوط به آنچه قبلا محاسبهشده را حفظ میکند. همین حافظه RNN پیچیدگی کلی شبکه عصبی را کاهش داده است.
الگوریتم RNN میتواند دادههای سری زمانی را تجزیهوتحلیل کند و توانایی ذخیره، یادگیری و نگهداری زمینههای اطلاعاتی با هر طول دادهای را دارد. RNN بیشتر در مواردی استفاده میشود که توالی زمانی از اهمیت بالایی برخوردار است، مانند تشخیص گفتار، ترجمه زبان، پردازش فریم ویدیو، تولید متن و شرح تصویر. برای مثال سیری، دستیار گوگل و افزونه گوگل ترنسلیت نیز از معماری RNN استفاده میکنند.
۱۱-الگوریتمهای کاهش ابعاد (Dimensionality Reduction Algorithms)
در دنیای امروز، حجم وسیعی از دادهها توسط شرکتها، سازمانهای دولتی و سازمانهای تحقیقاتی ذخیره و تجزیهوتحلیل میشود. طبیعتا این دادههای خام حاوی اطلاعات زیادی هستند و شناسایی الگوها و متغیرهای مهم در آنها برای دانشمندان داده یک چالش است.
الگوریتمهای کاهش ابعاد مانند الگوریتمهای درخت تصمیم و جنگل تصادفی میتوانند به یافتن جزئیات مرتبط به دادههای مشترک کمک کنند.
۱۲-الگوریتم تقویت گرادیان (Gradient Boosting Algorithm) و الگوریتم AdaBoosting
الگوریتم تقویت گرادیان و الگوریتم AdaBoosting الگوریتمهای تقویتی هستند که برای پیشبینیهایی با دقت بالا که باید حجم زیادی از دادهها را مدیریت کرد استفاده میشوند. میتوانید از این الگوریتمها به همراه کدهای پایتون و R، برای دستیابی به نتایج دقیق استفاده کنید.
مثلا Boosting یک الگوریتم یادگیری گروهی است که قدرت پیشبینی چندین تخمینگر پایه را برای بهبود استحکام ترکیب میکند. بهطور خلاصه این الگوریتم چندین پیشبینی ضعیف یا متوسط را برای ایجاد یک پیشبینی قوی ترکیب میکند.
جمعبندی
الگوریتمهای یادگیری ماشین دادهها را تجزیهوتحلیل میکنند، ارتباط و نتایج مربوط به دادههای ورودی را به خروجی ترسیم میکنند و الگوهای داده را تشخیص میدهند. این الگوریتمها بهطور خودکار اصلاح میشوند تا در طول زمان به بهبود ادامه دهند. یعنی با پردازش دادههای بیشتر هوشمندتر میشوند و عملکرد کلی پیشبینیشان دقیقتر خواهد بود.
با توجه به گسترش دامنه و زمینههای کاری و استفاده از ماشین لرنینگ در حوزههای مختلف، بسته به نیازهای متغیر و پیچیدگی مشکلات مختلف، انواع مختلفی از الگوریتمهای یادگیری ماشین وجود دارد که هرکدام کارایی و کاربردهای خودشان را دارند. پس میتوانید الگوریتمی را انتخاب کنید که به بهترین وجه با نیازهای کاری شما مطابقت دارد. در برخی موارد هم متخصصان ترکیبی از این الگوریتمها را استفاده میکنند، زیرا ممکن است یک الگوریتم بهتنهایی قادر به حل مشکل خاصی نباشد.
با شرکت در بوت کمپ آموزش ماشین لرنینگ در رهنما کالج میتوانید همهچیز را درباره یادگیری ماشین و تکنیکها و الگوریتمهای مختلف مربوط به آن بهصورت تخصصی و جامع یاد بگیرید.